

Tuesday, December 02, 2008
change.gov is the web site of Obama and Biden's transition to government, and they've licensed the content with a Creative Commons Attribution licence. Kudos.
But when I read about this on lessig.org, I went to change.gov and couldn't find any reference to Creative Commons. I looked at the HTML source and there was no reference to Creative Commons. It turns out that there is a page on the site about copyright policy, and this has a statement that covers all other pages on the site.
If this kind of licensing (having one page on your site that states that all other pages are licensed, and then linking to that page from all other pages on the site) is common (and I think it is), it means that just counting links to Creative Commons (or any other licence, for that matter) gives you a pretty bad estimation of the number of licensed pages out there.
As an example of what I'm talking about, consider the following comparison:
I beg to differ.
(For more on this topic, and some ways it can be tackled, see my paper from iSummit. And stay tuned for more.)
(via lessig.org, via reddit.com)
But when I read about this on lessig.org, I went to change.gov and couldn't find any reference to Creative Commons. I looked at the HTML source and there was no reference to Creative Commons. It turns out that there is a page on the site about copyright policy, and this has a statement that covers all other pages on the site.
If this kind of licensing (having one page on your site that states that all other pages are licensed, and then linking to that page from all other pages on the site) is common (and I think it is), it means that just counting links to Creative Commons (or any other licence, for that matter) gives you a pretty bad estimation of the number of licensed pages out there.
As an example of what I'm talking about, consider the following comparison:
- apsa.anu.edu.au, 230 pages linking to Creative Commons licences, of about 655 pages. (But please don't ask me which pages don't link to Creative Commons licences, because I can't figure it out. That would be another blog post.)
- change.gov, 1 page linking to a Creative Comons licence, of about 432 pages.
I beg to differ.
(For more on this topic, and some ways it can be tackled, see my paper from iSummit. And stay tuned for more.)
(via lessig.org, via reddit.com)
Labels: ben, isummit08, lessig, quantification
Thursday, July 31, 2008
I've done my presentation at iSummit in the research track. My paper should be available soon on the site too.
In the same session, there was also a great talk by Juan Carlos De Martin about geo-location of web pages, but it was actually broader than that and included quantification issues. Read more about that here.
Tomorrow, the research track is going to talk about the future of research about the commons. Stay tuned.
In the same session, there was also a great talk by Juan Carlos De Martin about geo-location of web pages, but it was actually broader than that and included quantification issues. Read more about that here.
Tomorrow, the research track is going to talk about the future of research about the commons. Stay tuned.
Labels: ben, isummit08, quantification, research
Friday, June 06, 2008
Wednesday, May 21, 2008
Here are the ways I can think of that an automated system could know that a web page is licensed:
- has a link to a known licence URL
- has a link that has rel="license" attribute in the tag, and a legal expert confirms that the link target is a licence URL
- has a meta tag with name="dc:rights" content="URL", and an expert confirms that the URL is a licence
- has embedded or external RDF+XML with license rdf:resource="URL"
- natural language, such as "This web page is licensed with a Creative Commons Attribution 1.0 Australia License"
- system is told by someone it trusts
- URL is in rel="license" link tag, expert confirms
- URL is in meta name="dc:rights" tag, expert confirms
- URL is in RDF license tag
- page contains an exact copy of a known licence
- system is told by someone it trusts
Labels: ben, quantification
Running for 8 hours, without crashing but with a little complaining about bad web pages, my analysis analysed 191,093 web pages (not other file types like images) and found 179 pages that have rel="license" links (a semantic statement that the page is licensed) with a total of 288 rel="license" links (about 1.5 per page). This equates to 1 in 1067 pages using rel="license"
The pages were drawn randomly from the dataset, though I'm not sure that my randomisation is great - I'll look into that. As I said in a previous post, the data aims to be a broad crawl of Australian sites, but it's neither 100% complete nor 100% accurate about sites being Australian.
By my calculations, if I were to run my analysis on the whole dataset, I'd expect to find approximately 1.3 million pages using rel="licence". But keep in mind that I'm not only running the analysis over three years of data, but that data also sometimes includes the same page more than once for a given year/crawl, though much more rarely than, say, the Wayback Machine does.
And of course, this statistic says nothing about open content licensing. I'm sure, as in I know, there are lots more pages out there that don't use rel="license".
(Tech note: when doing this kind of analysis, there's a race between I/O and processor time, and ideally they're both maxed out. Over last night's analysis, the CPU load - for the last 15 minutes at least, but I think that's representative - was 58%, suggesting that I/O is so far the limiting factor.)
The pages were drawn randomly from the dataset, though I'm not sure that my randomisation is great - I'll look into that. As I said in a previous post, the data aims to be a broad crawl of Australian sites, but it's neither 100% complete nor 100% accurate about sites being Australian.
By my calculations, if I were to run my analysis on the whole dataset, I'd expect to find approximately 1.3 million pages using rel="licence". But keep in mind that I'm not only running the analysis over three years of data, but that data also sometimes includes the same page more than once for a given year/crawl, though much more rarely than, say, the Wayback Machine does.
And of course, this statistic says nothing about open content licensing. I'm sure, as in I know, there are lots more pages out there that don't use rel="license".
(Tech note: when doing this kind of analysis, there's a race between I/O and processor time, and ideally they're both maxed out. Over last night's analysis, the CPU load - for the last 15 minutes at least, but I think that's representative - was 58%, suggesting that I/O is so far the limiting factor.)
Labels: ben, quantification, research
Monday, May 19, 2008
The National Library of Australia has been crawling the Australian web (defining the Australian web is of course an issue in itself). I'm going to be running some quantification analysis over at least some of this crawl (actually plural, crawls - there is a 2005 crawl, a 2006 crawl and a 2007 crawl), probably starting with a small part of the crawl and then scaling up.
Possible outcomes from this include:
Possible outcomes from this include:
- Some meaningful consideration of how many web pages, on average, come about from a single decision to use a licence. For example, if you licence your blog and put a licence statement into your blog template, that would be one decision to use the licence, arguably one licensed work (your blog), but actually 192 web pages (with permalinks and all). I've got a few ideas about how to measure this, which I can go in to more depth about.
- How much of the Australian web is licensed, both proportionally (one page in X, one web site in X, or one 'document' in X), and in absolute terms (Y web pages, Y web sites, Y 'documents').
- Comparison of my results to proprietary search-engine based answers to the same question, to put my results in context.
- Comparison of various licensing mechanisms, including but not limited to: hyperlinks, natural language statements, dc rights in tags, rdf+xml.
- Comparison of use of various licences, and licensing elements.
- Changes in the answers to these questions over time.
Labels: ben, licensing, open content, quantification, research
Wednesday, April 30, 2008
Google Code Search lets you search for source code files by licence type, so of course I was interested in whether this could be used for quantifying indexable source code on the web. And luckily GCS lets you search for all works with a given licence. (If you don't understand why that's a big deal, try doing a search for all Creative Commons licensed work using Google Search.) Even better, using the regex facility you can search for all works! You sure as heck can't do that with a regular Google web search.
Okay, so here's the latest results, including hyperlinks to searches for you to try them yourself:
And here's a spreadsheet with graph included: However, note the discontinuity (in absolute and trend terms) between approximate and specific results in that (logarithmic) graph, which suggests Google's approximations are not very good.
Okay, so here's the latest results, including hyperlinks to searches for you to try them yourself:
- all (by regex: .*) : 36,700,000
- gpl : 8,960,000
- lgpl : 4,640,000
- bsd : 3,110,000
- mit : 903,000
- cpl : 136,000
- artistic : 192
- apache : 156
- disclaimer : 130
- python : 108
- zope : 103
- mozilla : 94
- qpl : 86
- ibm : 67
- sleepycat : 51
- apple : 47
- lucent : 19
- nasa : 15
- alladin : 9
And here's a spreadsheet with graph included: However, note the discontinuity (in absolute and trend terms) between approximate and specific results in that (logarithmic) graph, which suggests Google's approximations are not very good.
Labels: ben, free software, licensing, quantification, search
Tuesday, April 08, 2008
Hi commons researchers,
I just did this analysis of Google's and Yahoo's capacities for search for commons (mostly Creative Commons because that's in their advanced search interfaces), and thought I'd share. Basically it's an update of my research from Finding and Quantifying Australia's Online Commons. I hope it's all pretty self-explanatory. Please ask questions. And of course point out flaws in my methods or examples.
Also, I just have to emphasise the "No" in Yahoo's column in row 1: yes, I am in fact saying that the only jurisdiction of licences that Yahoo recognises is the US/unported licences, and that they are in fact ignoring the vast majority of Creative Commons licences. (That leads on to a whole other conversation about quantification, but I'll leave that for now.)
(I've formatted this table in Courier New so it should come out well-aligned, but who knows).
Feature | Google | Yahoo |
------------------------------+--------+-------+
1. Multiple CC jurisdictions | Yes | No | (e.g.)
2. 'link:' query element | No | Yes | (e.g. G, Y)
3. RDF-based CC search | Yes | No | (e.g.)
4. meta name="dc:rights" * | Yes | ? ** | (e.g.)
5. link-based CC search | No | Yes | (e.g.)
6. Media-specific search | No | No | (G, Y)
7. Shows licence elements | No | No | ****
8. CC public domain stamp *** | Yes | Yes | (e.g.)
9. CC-(L)GPL stamp | No | No | (e.g.)
* I can't rule out Google's result here actually being from <a rel="license"> in the links to the license (as described here: http://microformats.org/wiki/rel-license).
** I don't know of any pages that have <meta name="dc:rights"> metadata (or <a rel="licence"> metadata?) but don't have links to licences.
*** Insofar as the appropriate metadata is present.
**** (i.e. doesn't show which result uses which licence)
Notes about example pages (from rows 1, 3-5, 8-9):
I just did this analysis of Google's and Yahoo's capacities for search for commons (mostly Creative Commons because that's in their advanced search interfaces), and thought I'd share. Basically it's an update of my research from Finding and Quantifying Australia's Online Commons. I hope it's all pretty self-explanatory. Please ask questions. And of course point out flaws in my methods or examples.
Also, I just have to emphasise the "No" in Yahoo's column in row 1: yes, I am in fact saying that the only jurisdiction of licences that Yahoo recognises is the US/unported licences, and that they are in fact ignoring the vast majority of Creative Commons licences. (That leads on to a whole other conversation about quantification, but I'll leave that for now.)
(I've formatted this table in Courier New so it should come out well-aligned, but who knows).
Feature | Google | Yahoo |
------------------------------+--------+-------+
1. Multiple CC jurisdictions | Yes | No | (e.g.)
2. 'link:' query element | No | Yes | (e.g. G, Y)
3. RDF-based CC search | Yes | No | (e.g.)
4. meta name="dc:rights" * | Yes | ? ** | (e.g.)
5. link-based CC search | No | Yes | (e.g.)
6. Media-specific search | No | No | (G, Y)
7. Shows licence elements | No | No | ****
8. CC public domain stamp *** | Yes | Yes | (e.g.)
9. CC-(L)GPL stamp | No | No | (e.g.)
* I can't rule out Google's result here actually being from <a rel="license"> in the links to the license (as described here: http://microformats.org/wiki/rel-license).
** I don't know of any pages that have <meta name="dc:rights"> metadata (or <a rel="licence"> metadata?) but don't have links to licences.
*** Insofar as the appropriate metadata is present.
**** (i.e. doesn't show which result uses which licence)
Notes about example pages (from rows 1, 3-5, 8-9):
- To determine whether a search engine can find a given page, first look at the page and find enough snippets of content that you can create a query that definitely returns that page, and test that query to make sure the search engine can find it (e.g. '"clinton lies again" digg' for row 8). Then do the same search as an advanced search with Creative Commons search turned on and see if the result is still found.
- The example pages should all be specific with respect to the feature they exemplify. E.g. the Phylocom example from row 9 has all the right links, logos and metadata for the CC-GPL, and particularly does not have any other Creative Commons licence present, and does not show up in search results.
Labels: ben, Creative Commons, quantification, search
Tuesday, February 19, 2008
(following on from this post)
http://www.archive.org/web/researcher/intended_users.php
I'll certainly be looking into this further.
(update: On further investigation, it doesn't look so good. http://www.archive.org/web/researcher/researcher.php says:
http://www.archive.org/web/researcher/intended_users.php
I'll certainly be looking into this further.
(update: On further investigation, it doesn't look so good. http://www.archive.org/web/researcher/researcher.php says:
We are in the process of redesigning our researcher web interface. During this time we regret that we will not be able to process any new researcher requests. Please see if existing tools such as the Wayback Machine can accommodate your needs. Otherwise, check back with us in 3 months for an update.This seems understandable except for this, on the same page:
This material has been retained for reference and was current information as of late 2002.That's over 5 years. And in Internet time, that seems like a lifetime. I'll keep investigating.)
Labels: ben, open access, quantification
There is a problem with search engines at the moment. Not any one in particular - I'm not saying Google has a problem. Google seems to be doing what they do really well. Actually, the problem is not so much something that is being done wrong, but something that is just not being done. Now, if you'll bear with me for a moment...
The very basics of web search
Web search engines, like Google, Yahoo, Live, etc., are made up of a few technologies:
But what I'm interested in here is web crawling. Perhaps that has something to do with the fact that online commons quantification doesn't require indexing or performing searches. But bear with me - I think it's more than that.
A bit more about the web crawler
There are lots of tricky technical issues about how to do the best crawl - to cover as many pages as possible, to have the most relevant pages possible, to maintain the latest version of the pages. But I'm not worried about this now. I'm just talking about the fundamental problem of downloading web pages for later use.
Anyone who is reading this and hasn't thought about the insides of search engines before is probably wondering at the sheer amount of downloading of web pages required, and storing them. And you should be.
They're all downloading the same data
So a single search engine basically has to download the whole web? Well, some certainly have to try. Google, Yahoo and Live are trying. I don't know how many others are trying, and many of them may not be publicly using their data so we may not see them. There clearly are more at least than I've ever heard of - take a look at Wikipedia's robots.txt file: http://en.wikipedia.org/robots.txt.
My point is why does everyone have to download the same data? Why isn't there some open crawler somewhere that's doing it all for everyone, and then presenting that data through some simple interface? I have a personal belief that when someone says 'should', you should* be critical in listening to them. I'm not saying here that Google should give away their data - it would have to be worth $millions to them. I'm not saying anyone else should be giving away all their data. But I am saying that there should be someone doing this, from an economic point of view - everyone is downloading the same data, and there's a cost to doing that, and the cost would be smaller if they could get together and share their data.
Here's what I'd like to see specifically:
* I know.
The very basics of web search
Web search engines, like Google, Yahoo, Live, etc., are made up of a few technologies:
- Web crawling - downloading web pages; discovering new web pages
- Indexing - like the index in a book: figure out which pages have which features (meaning keywords, though there may be others), and store them in separate lists for later access
- Performing searches - when someone wants to do a keyword search, for example, the search engine can look up the keywords in the index, and find out which pages are relevant
But what I'm interested in here is web crawling. Perhaps that has something to do with the fact that online commons quantification doesn't require indexing or performing searches. But bear with me - I think it's more than that.
A bit more about the web crawler
There are lots of tricky technical issues about how to do the best crawl - to cover as many pages as possible, to have the most relevant pages possible, to maintain the latest version of the pages. But I'm not worried about this now. I'm just talking about the fundamental problem of downloading web pages for later use.
Anyone who is reading this and hasn't thought about the insides of search engines before is probably wondering at the sheer amount of downloading of web pages required, and storing them. And you should be.
They're all downloading the same data
So a single search engine basically has to download the whole web? Well, some certainly have to try. Google, Yahoo and Live are trying. I don't know how many others are trying, and many of them may not be publicly using their data so we may not see them. There clearly are more at least than I've ever heard of - take a look at Wikipedia's robots.txt file: http://en.wikipedia.org/robots.txt.
My point is why does everyone have to download the same data? Why isn't there some open crawler somewhere that's doing it all for everyone, and then presenting that data through some simple interface? I have a personal belief that when someone says 'should', you should* be critical in listening to them. I'm not saying here that Google should give away their data - it would have to be worth $millions to them. I'm not saying anyone else should be giving away all their data. But I am saying that there should be someone doing this, from an economic point of view - everyone is downloading the same data, and there's a cost to doing that, and the cost would be smaller if they could get together and share their data.
Here's what I'd like to see specifically:
- A good web crawler, crawling the web and thus keeping an up-to-date cache of the best parts of the web
- An interface that lets you download this data, or diffs from a previous time
- An interface that lets you download just some. E.g. "give me everything you've got from cyberlawcentre.org/unlocking-ip" or "give me everything you've got from *.au (Australian registered domains)" or even "give me everything you've got that links to http://labs.creativecommons.org/licenses/zero-assert/1.0/us/"
- Note that in these 'interface' points, I'm talking about downloading data in some raw format, that you can then use to, say, index and search with your own search engine.
* I know.
Labels: ben, open access, quantification, search
Monday, February 18, 2008
As you aren't aware*, Creative Commons has some data on the quantification of Creative Commons licence usage (collected using search engine queries). It's great that they are a) collecting this data, and b) sharing it freely.
If you look around, you can probably find some graphs based on this data, and that's probably interesting in itself. Tomorrow I'll see about dusting off my Perl skills, and hopefully come up with a graph of the growth of Australian CC licence usage. Stay tuned.
* If you knew about this, why didn't you tell me!
If you look around, you can probably find some graphs based on this data, and that's probably interesting in itself. Tomorrow I'll see about dusting off my Perl skills, and hopefully come up with a graph of the growth of Australian CC licence usage. Stay tuned.
* If you knew about this, why didn't you tell me!
Labels: ben, Creative Commons, licensing, quantification
Friday, July 06, 2007
Those of you who have been paying (very) close attention would have noticed that there was one thing missing from yesterday's post - the very same topic on which I've been published: quantification of online commons.
This is set to be a continuing theme in my research. Not because it's particularly valuable in the field of computer science, but because in the (very specific) field of online commons research, no one else seems to be doing much. (If you know something I don't about where to look for the research on this, please contact me now!)
I wish I could spend more time on this. What I'd do if I could would be another blog post altogether. Suffice it to say that I envisaged a giant machine (completely under my control), frantically running all over the Internets counting documents and even discovering new types of licences. If you want to hear more, contact me, or leave a comment here and convince me to post on it specifically.
So what do I have to say about this? Actually, so much that the subject has its own page. It's on unlockingip.org, here. It basically surveys what's around on the subject, and a fair bit of that is my research. But I would love to hear about yours or any one else's, published, unpublished, even conjecture.
Just briefly, here's what you can currently find on the unlockingip.org site:
I'm also interested in the methods of quantification. With the current technologies, what is the best way to find out, for any given licence, how many documents (copyrighted works) are available with increased public rights? This is something I need to put to Creative Commons, because their licence statistics page barely addresses this issue.
This is set to be a continuing theme in my research. Not because it's particularly valuable in the field of computer science, but because in the (very specific) field of online commons research, no one else seems to be doing much. (If you know something I don't about where to look for the research on this, please contact me now!)
I wish I could spend more time on this. What I'd do if I could would be another blog post altogether. Suffice it to say that I envisaged a giant machine (completely under my control), frantically running all over the Internets counting documents and even discovering new types of licences. If you want to hear more, contact me, or leave a comment here and convince me to post on it specifically.
So what do I have to say about this? Actually, so much that the subject has its own page. It's on unlockingip.org, here. It basically surveys what's around on the subject, and a fair bit of that is my research. But I would love to hear about yours or any one else's, published, unpublished, even conjecture.
Just briefly, here's what you can currently find on the unlockingip.org site:
- My SCRIT-ed paper
- My research on the initial uptake of the Creative Commons version 2.5 (Australia) licence
- Change in apparent Creative Commons usage, June 2006 - March 2007
- Creative Commons semi-official statistics
I'm also interested in the methods of quantification. With the current technologies, what is the best way to find out, for any given licence, how many documents (copyrighted works) are available with increased public rights? This is something I need to put to Creative Commons, because their licence statistics page barely addresses this issue.
Labels: ben, quantification, research
Wednesday, March 14, 2007
In June last year, I presented a paper at the Unlocking IP conference, part of which involved collecting data on Australian usage of Creative Commons licences. For example, here's the data I collected in June 2006, organised by licence attribute:
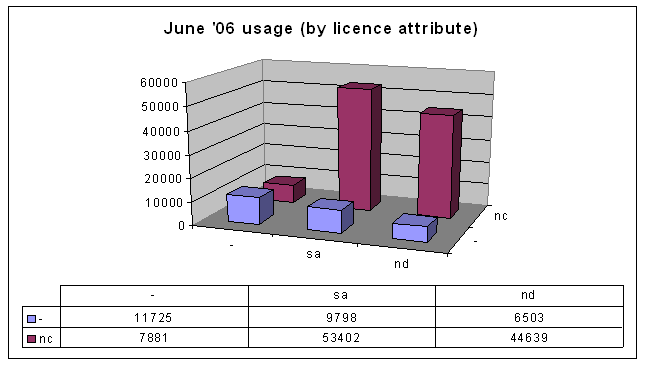 It shows that most people are using the Non-Commercial licences and restricting derivative works.
It shows that most people are using the Non-Commercial licences and restricting derivative works.
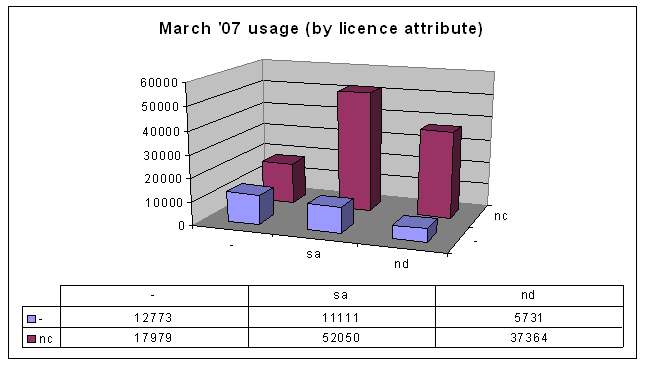
That was all well and good, but then this year I revised my paper for publication in SCRIPT-ed. I wasn't going to gather the data all over again, but then I remembered that Australia now has version 2.5 Creative Commons licences, and I guessed (correctly) that the numbers would be big enough to warrant being included in the paper. Here's the data from March 2007:
Matrix subtraction
I admit that it looks about the same, but it gets interesting when you subtract the old data from the new data, to find the difference between now and mid-2006:
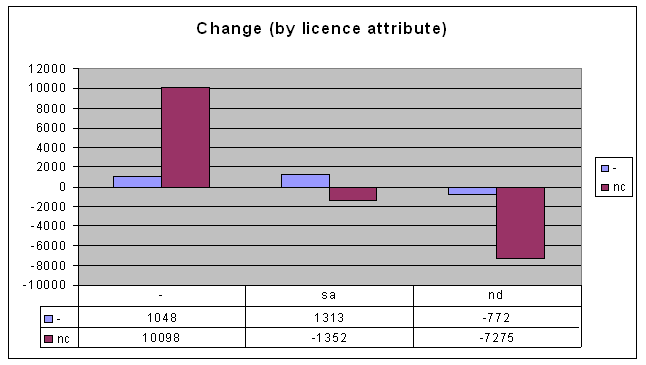 So here's my first conclusion, from looking at this graph:
So here's my first conclusion, from looking at this graph:
The jurisdiction/version dimension
Another way of looking at the data is by jurisdiction and version, instead of by the licences' attributes. Here's the data from June 2006, organised this way:
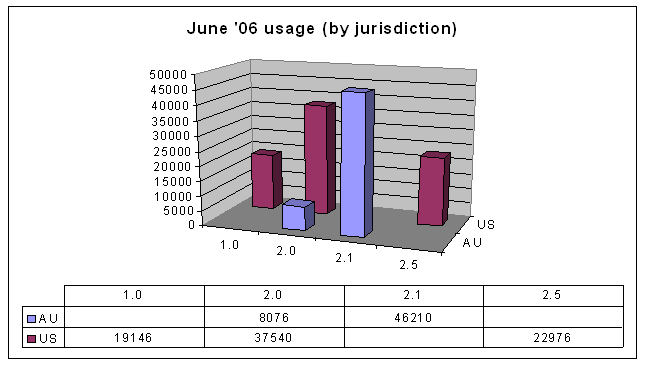 First, note that there was no data (at the time) for Australian version 1.0 and 2.5, and US version 2.1 licences. This is simply because not all jurisdictions have all licence versions.
First, note that there was no data (at the time) for Australian version 1.0 and 2.5, and US version 2.1 licences. This is simply because not all jurisdictions have all licence versions.
Some people might be wondering at this stage why there are Australian web sites using US licences. I believe the reason is that Creative Commons makes it very easy to use US (now generic) licences. See http://creativecommons.org/license/, where the unported licence is the default option.
The previous graph, also, is not particularly interesting in itself, but compare that to the current data:
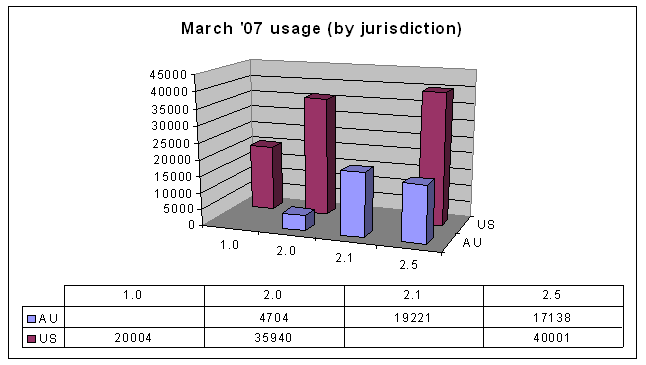
The move away from Australia version 2.1
You can see straight away that there's lots of change in the 2.1 and 2.5 version licences. But take a look at the change over the last 9 months:
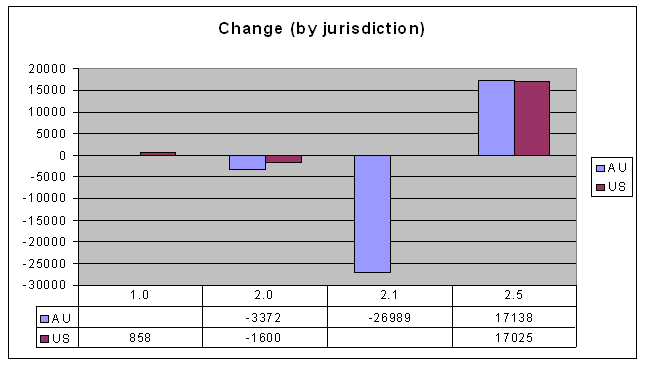 Can that be right? Australian usage of both US and Australian version 2.5 licences has increased as expected (because they are current). But why would the usage of Australian 2.1 licences go down? And by more than the amount of new usage of Australian 2.5 licences? Here are some possibilities:
Can that be right? Australian usage of both US and Australian version 2.5 licences has increased as expected (because they are current). But why would the usage of Australian 2.1 licences go down? And by more than the amount of new usage of Australian 2.5 licences? Here are some possibilities:
Methodology
For the record, here's how I collected the data. I did the following Yahoo searches (and 36 others). For each search, Yahoo tells you "about" how many pages are found.
Last word
You can see a graph of the change in usage for every licence for every version and both jurisdictions here.
It shows that most people are using the Non-Commercial licences and restricting derivative works.That was all well and good, but then this year I revised my paper for publication in SCRIPT-ed. I wasn't going to gather the data all over again, but then I remembered that Australia now has version 2.5 Creative Commons licences, and I guessed (correctly) that the numbers would be big enough to warrant being included in the paper. Here's the data from March 2007:
Matrix subtraction
I admit that it looks about the same, but it gets interesting when you subtract the old data from the new data, to find the difference between now and mid-2006:
So here's my first conclusion, from looking at this graph:- People are moving away from Attribution-NonCommercial-NoDerivs licences and towards Attribution-NonCommercial licences. I.e. people are tending towards allowing modifications of their works.
The jurisdiction/version dimension
Another way of looking at the data is by jurisdiction and version, instead of by the licences' attributes. Here's the data from June 2006, organised this way:
First, note that there was no data (at the time) for Australian version 1.0 and 2.5, and US version 2.1 licences. This is simply because not all jurisdictions have all licence versions.Some people might be wondering at this stage why there are Australian web sites using US licences. I believe the reason is that Creative Commons makes it very easy to use US (now generic) licences. See http://creativecommons.org/license/, where the unported licence is the default option.
The previous graph, also, is not particularly interesting in itself, but compare that to the current data:
The move away from Australia version 2.1
You can see straight away that there's lots of change in the 2.1 and 2.5 version licences. But take a look at the change over the last 9 months:
Can that be right? Australian usage of both US and Australian version 2.5 licences has increased as expected (because they are current). But why would the usage of Australian 2.1 licences go down? And by more than the amount of new usage of Australian 2.5 licences? Here are some possibilities:- Some people who were using AU-2.1 licences have switched to AU-2.5, and some have switched to US-2.5 (the latter's a little hard to understand, though).
- The AU-2.1 licence usage has gone down independent of the new licences. It could even be that most of the licences were actually not real licensed works, but, for example, error messages on a web site that has a licence stamp on every page. If the web site is inadvertently exposing countless error messages, when the problem is fixed it could involve this kind of correction.
- Or my original data could have just been wrong. I know it's not cool to suggest this kind of thing: "my data? My data! There's nothing wrong with my data!" Well, even then, it could be that my methods have significant variability.
Methodology
For the record, here's how I collected the data. I did the following Yahoo searches (and 36 others). For each search, Yahoo tells you "about" how many pages are found.
- Australian use of AU-by version 2.5
- Australian use of AU-by-sa version 2.5
- Australian use of AU-by-nd version 2.5
- Australian use of AU-by-nc version 2.5
- Australian use of AU-by-nc-sa version 2.5
- Australian use of AU-by-nc-nd version 2.5
Last word
You can see a graph of the change in usage for every licence for every version and both jurisdictions here.
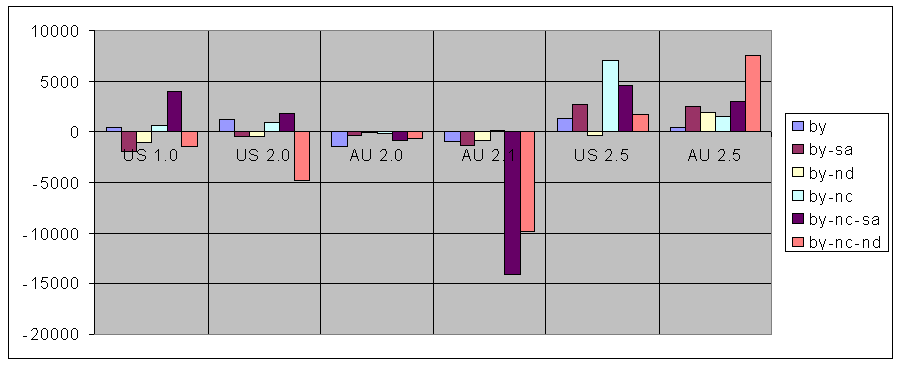{kind=link}
Labels: ben, Creative Commons, quantification
![]()